Un estudio de investigación Claude Code para un productor de documentales
Construimos un estudio privado de investigación y escritura con IA para un productor de documentales que presenta proyectos a las mayores cadenas públicas de Alemania. Hieronymus Vault combina una base de conocimiento Obsidian nativa, un corpus estilométrico versionado, skills propias de Claude Code y una arquitectura multiagente en fan-out. De la idea al DOCX listo para emisión en menos de tres horas. En su voz. Cada afirmación trazable a su fuente.
- Ubicación
- Hamburg, Germany
- Duración
- 2 weeks
El reto
Un solo encargo documental se mueve en cifras de seis o siete dígitos y depende de un exposé de quince páginas entregado a una responsable de programación en el tono exacto. Los productores entregan decenas de estos cada año. Cada uno exige investigación histórica profunda entre continentes, análisis de huecos en la programación del canal, casting de expertos y escritura en una voz que la redacción reconoce al instante. El trabajo es creativo; el sustrato es ingeniería. Tipografía determinista, trazabilidad de cada afirmación, fidelidad vocal bajo generación y cero deriva de tono en cientos de páginas. Un solo exposé frágil pierde el encargo. Nuestro cliente necesitaba un sistema que multiplicara su producción sin aplanar su voz ni su exigencia.
La solución
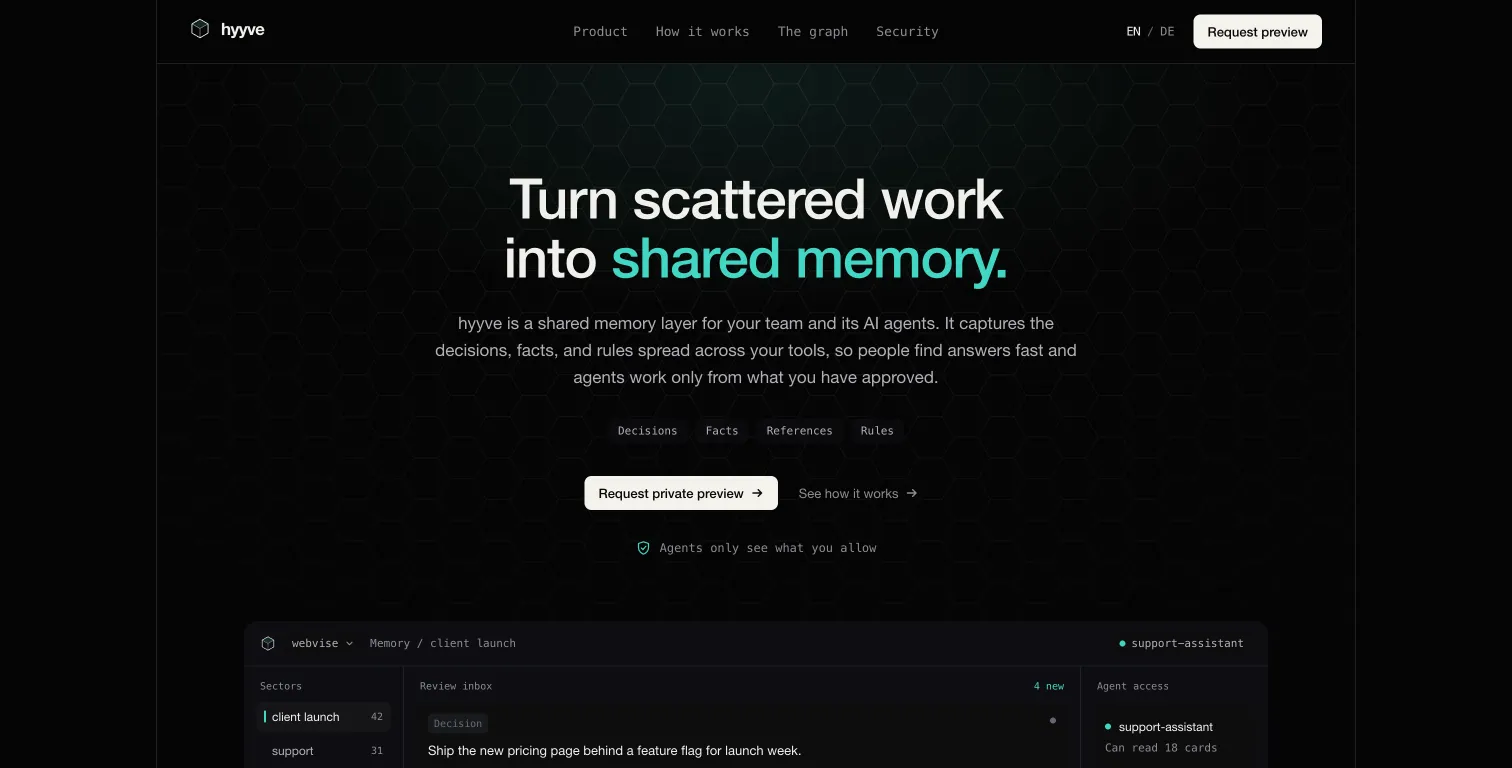
Construimos Hieronymus Vault, un estudio de investigación orquestado con Claude Code en torno a una única bóveda Obsidian que funciona a la vez como base de conocimiento, corpus estilométrico y traza de auditoría append-only. Frontmatter YAML validado por esquema en nueve clases de entidad tipadas hace cada nota navegable por máquina sin una capa de base de datos. Un índice semántico sobre la bóveda sostiene el recall multitemático sin salir del bucle de orquestación. Ocho de sus pitches existentes se ingeniaron a la inversa en un corpus de voz versionado dentro del cual escribe el modelo. Una skill propia /zdfinfo-format carga esa voz y despliega sub-agentes de investigación paralelos (document-specialist, scientist, executor, explore) sobre fuentes, casting de expertos y análisis de huecos del canal. Cada sub-agente corre en una ventana de contexto aislada para que las líneas de investigación no se mezclen; la síntesis se hace en el agente principal. Una capa de vigilancia autónoma consulta cada treinta minutos, las veinticuatro horas, los portales de encargos, las publicaciones de archivos y las noticias. El exposé final se renderiza como DOCX listo para emisión en la identidad corporativa del editor mediante plantillas python-docx con tipografía determinista. Un viaje de ida y vuelta con el coautor reincorpora cada edición externa a la bóveda, la compara con la revisión anterior y alimenta el delta estilístico al corpus de voz, de modo que el sistema se sigue ajustando por ciclo.
Sebastian me construyó algo que no he visto en el mercado. Un estudio de investigación que piensa en mi voz, escanea los feeds de las cadenas mientras duermo y renderiza el DOCX final en la CI sin que toque una sola plantilla. La bóveda es ahora donde mi trabajo realmente vive. Pitcho más, más fino, más rápido.

Tech Stack
Inicie su proyecto
Describa el flujo, los usuarios, las herramientas y las restricciones. webvise lo convierte en un plan claro con calendario y presupuesto antes de empezar la implementación.
Iniciar un proyecto